
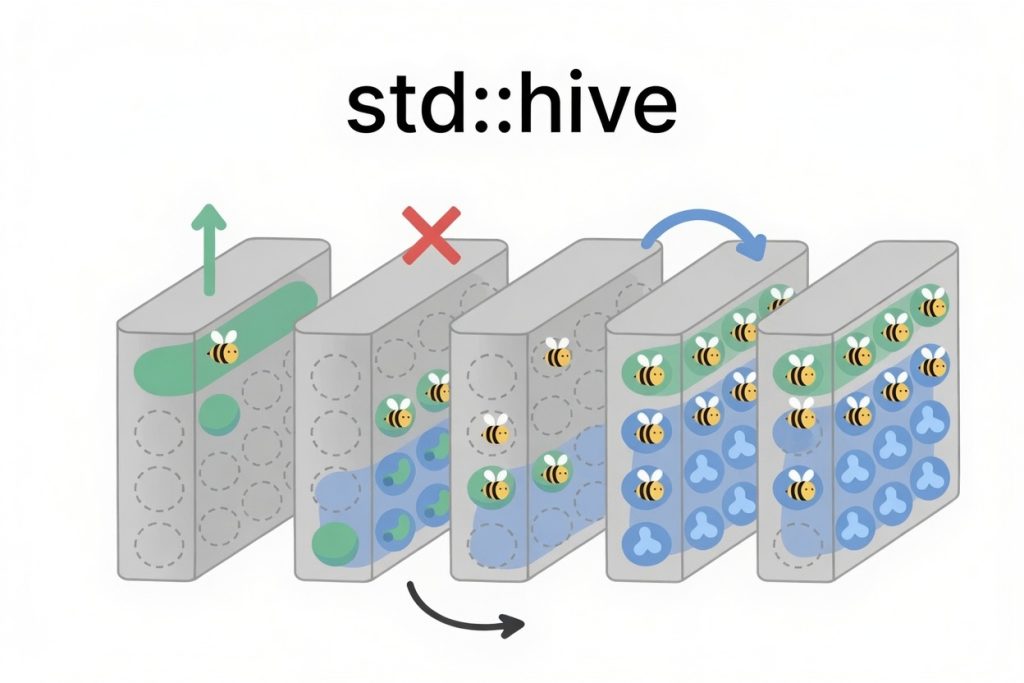
 How fast is C++26’s std::hive?C++26 adds a new container to the standard library: std::hive. It is meant to occupy the ground between std::vector and std::list. Like a vector, it keeps its elements in contiguous blocks of memory, so scanning it does not require you to chase a pointer for every element. Like a list, it never moves an element … Continue reading How fast is C++26’s std::hive?📝Daniel Lemire's blog
How fast is C++26’s std::hive?C++26 adds a new container to the standard library: std::hive. It is meant to occupy the ground between std::vector and std::list. Like a vector, it keeps its elements in contiguous blocks of memory, so scanning it does not require you to chase a pointer for every element. Like a list, it never moves an element … Continue reading How fast is C++26’s std::hive?📝Daniel Lemire's blogWelcome to SwedenCpp
Latest blogs, videos, podcasts and releases in one stream
Sunday, August 2, 2026
How fast is C++26’s std::hive?C++26 adds a new container to the standard library: std::hive. It is meant to occupy the ground between std::vector and std::list. Like a vector, it keeps its elements in contiguous blocks of memory, so scanning it does not require you to chase a pointer for every element. Like a list, it never moves an element … Continue reading How fast is C++26’s std::hive?📝Daniel Lemire's blog Why Did C++ Invent nullptr? NULL Wasn't Good Enough! 🤯🎥CppNuts
Why Did C++ Invent nullptr? NULL Wasn't Good Enough! 🤯🎥CppNuts When Abstractions Fix Too Much - Towards Flexible Library Design - Patrick Roberts - C++Now 2026🎥CppNow
When Abstractions Fix Too Much - Towards Flexible Library Design - Patrick Roberts - C++Now 2026🎥CppNow BeCPP Symposium 2026 - Phil Nash - Contemporary C++ Testing🎥BeCPP Users Group
BeCPP Symposium 2026 - Phil Nash - Contemporary C++ Testing🎥BeCPP Users Group How to Write Scalable, Deterministic Audio Engines - Janus Lynggaard Thorborg - ADCx Copenhagen 2026🎥audiodevcon
How to Write Scalable, Deterministic Audio Engines - Janus Lynggaard Thorborg - ADCx Copenhagen 2026🎥audiodevcon destructors [C++ Shorts Lesson 29]🎥Mike Shah
destructors [C++ Shorts Lesson 29]🎥Mike ShahIf this page is useful, please consider donating a coffee
Saturday, August 1, 2026
 emplace back vs push back🎥CppNuts
emplace back vs push back🎥CppNuts Vienna Game Geometry Library: a collision detection library for games - Fabian Haßlacher🎥MeetingCpp
Vienna Game Geometry Library: a collision detection library for games - Fabian Haßlacher🎥MeetingCpp imgui simple example with glfw [Episode 2 of 2]🎥Mike Shah
imgui simple example with glfw [Episode 2 of 2]🎥Mike ShahFriday, July 31, 2026
 Is emplace_back() REALLY Faster Than push_back()? 🤔 | C++🎥CppNuts
Is emplace_back() REALLY Faster Than push_back()? 🤔 | C++🎥CppNuts IEEE International Geoscience and Remote Sensing Symposium (IGARSS) 2026August 9-14, 2026 | Washington, D.C. Kitware is excited to participate in the IEEE International Geoscience and Remote Sensing Symposium (IGARSS) 2026 in Washington, D.C. Each year, IGARSS brings together the global remote sensing community to share research, discuss emerging technologies, and build new collaborations. This year’s theme, The Future of Earth Observations, reflects the […]📝Kitware Inc
IEEE International Geoscience and Remote Sensing Symposium (IGARSS) 2026August 9-14, 2026 | Washington, D.C. Kitware is excited to participate in the IEEE International Geoscience and Remote Sensing Symposium (IGARSS) 2026 in Washington, D.C. Each year, IGARSS brings together the global remote sensing community to share research, discuss emerging technologies, and build new collaborations. This year’s theme, The Future of Earth Observations, reflects the […]📝Kitware Inc Making an agile version of a Windows Runtime delegate in C++/WinRT, part 10What failure of the context callback means. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 10 appeared first on The Old New Thing .📝The Old New Thing
Making an agile version of a Windows Runtime delegate in C++/WinRT, part 10What failure of the context callback means. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 10 appeared first on The Old New Thing .📝The Old New Thing A Path to Practically Safe C++ - Yitzhak Mandelbaum - C++Now 2026🎥CppNow
A Path to Practically Safe C++ - Yitzhak Mandelbaum - C++Now 2026🎥CppNow From LLM Theory to Practical Agentic Implementations - Seth Juarez🎥NDC Conferences
From LLM Theory to Practical Agentic Implementations - Seth Juarez🎥NDC Conferences Legacy Architecture Migration Patterns with DDD - Nick Tune - NDC Toronto 2026🎥NDC Conferences
Legacy Architecture Migration Patterns with DDD - Nick Tune - NDC Toronto 2026🎥NDC Conferences Prompt-Jacking: The Rise of a New Supply Chain Risk - Kasimir Schulz & Kenneth Yeung🎥NDC Conferences
Prompt-Jacking: The Rise of a New Supply Chain Risk - Kasimir Schulz & Kenneth Yeung🎥NDC Conferences Use a Rust SAT Solver to play better pickleball! - Bob McNaughton - NDC Toronto 2026🎥NDC Conferences
Use a Rust SAT Solver to play better pickleball! - Bob McNaughton - NDC Toronto 2026🎥NDC Conferences Building AI That Learns and Adapts: A Case Study in MRI Diagnostics - Agata Chudzińska🎥NDC Conferences
Building AI That Learns and Adapts: A Case Study in MRI Diagnostics - Agata Chudzińska🎥NDC Conferences Everything you learned about SSL is deprecated - Todd Gardner - NDC Toronto 2026🎥NDC Conferences
Everything you learned about SSL is deprecated - Todd Gardner - NDC Toronto 2026🎥NDC Conferences "Looks Good to Me": A Practical Guide to Handling AI-Generated Code - Roman Zhukov🎥NDC Conferences
"Looks Good to Me": A Practical Guide to Handling AI-Generated Code - Roman Zhukov🎥NDC Conferences Kinton Ford’s _Canto I_In “Varaldo’s Shahrazad and Chiti’s Centunesimo Canto” (2025-08-11) I mentioned the existence of a lipogrammatic translation of Canto I of Dante’s Inferno performed by one Kinton Ford (a pseudonym, as far as I know) for Rick Whitaker’s now-defunct literary e-zine Exquisite Pandemic (2020–2021). A year later, seeing it’s still unavailable anywhere else online, I feel justified in preserving that whole tour-de-force here for posterity.📝Arthur O’Dwyer
Kinton Ford’s _Canto I_In “Varaldo’s Shahrazad and Chiti’s Centunesimo Canto” (2025-08-11) I mentioned the existence of a lipogrammatic translation of Canto I of Dante’s Inferno performed by one Kinton Ford (a pseudonym, as far as I know) for Rick Whitaker’s now-defunct literary e-zine Exquisite Pandemic (2020–2021). A year later, seeing it’s still unavailable anywhere else online, I feel justified in preserving that whole tour-de-force here for posterity.📝Arthur O’DwyerThursday, July 30, 2026
 The C++ Interview Book is hereFive years ago I published Daily C++ Interview — a collection of questions and answers that grew out of an email course I ran for C++ developers preparing for interviews. It did better than I expected. Over a thousand copies sold and plenty of kind emails from readers who found it genuinely helpful while preparing for their next role. Over time, the feedback made one thing clear: the book deser...📝Sandor Dargo's Blog
The C++ Interview Book is hereFive years ago I published Daily C++ Interview — a collection of questions and answers that grew out of an email course I ran for C++ developers preparing for interviews. It did better than I expected. Over a thousand copies sold and plenty of kind emails from readers who found it genuinely helpful while preparing for their next role. Over time, the feedback made one thing clear: the book deser...📝Sandor Dargo's Blog CMake 4.4.1 available for downloadCMake 4.4.1 available for download📝Kitware Inc
CMake 4.4.1 available for downloadCMake 4.4.1 available for download📝Kitware Inc Fixing a super 8 projector from the 70sWarning! Do not try any of this at home! Messing with internals of electronic devices is dangerous and can lead to electrical fires, serious injury and even loss of life. My dad started using a super 8 film camera as early as 1967 (the system was launched in 1965). He stopped doing it in the 1980s as it became pretty much impossible to buy film. Ever since then the films have been stored in multiple cardboard boxes in his basement. Recently he moved to a smaller apartment so all the films and related hardware had to go somewhere else. Namely, to me. Here is a representative sample. The picture does really not make justice to the projector. It is perhaps the only household appliance I have ever owned that could survive a head-on collision with an IBM Thinkpad from the 2000s. The projector weighs 10 kilos and consumes 200 watts when running, half of which is taken by its halogen light bulb. For comparison a typical modern LED light bulb consumes less than 5 watts. The projector has not been used this millennium so unsurprisingly it did nothing when I plugged it in. The back cover could be opened (with a screwdriver) revealing two glass fuses, one of which was burnt. I replaced it and plugged the machine back in. It immediately let loose the magic smoke even though everything was turned off. Fortunately I had kept the back cover open so could see the smoke the second it appeared and managed to cut the power before flames appeared. Unfortunately the smoke originated deep inside the machine so I could not see which component was the source. To get deeper I would have to remove all the covers. That is no small feat, mind you, I had to buy a whole new ratchet set to get all the various screws out. This thing predates printed circuit boards that would tell you which holes belong to which components. Instead all components have been soldered to the board by hand with Japanese meticulousness. The board won't give us any help on deciphering how things should work. Visual inspection also does not reveal any immediately broken components. Neither did poking around with a multimeter. The only life line was that even though a component had started smoking the fuse had not blown. In theory I could plug the machine in for a second and see if smoke appears again. If it does I can see the exact faulty component. At this point I'd like to remind you of the warning at the top of the post. If you have a known broken electrical device, you should never connect it to any sort of a power source. Seek advice from a qualified professional instead. Even if you manage not to burn your house down, electric shocks are nasty and any resulting smoke is almost certainly noxious. Anyhow, after taking sufficient precautions I plugged it back in and immediately got smoke and could decipher what was wrong. One of the main electrolytic capacitors (the one that was in the most inconvenient location, obviously) had dried out and shorted. This caused one of the bridge rectifiers to have its positive and negative output leads short circuited. Here are the problematic components. The dark blue capacitor on the right is the broken one. For some weird reason the three decoupling capacitors have different voltage ratings (16V, 25V and 50V) even though there is only one transformer and input voltage (12 V). The black circles are the bridge rectifiers. The one on the right is the broken one. In this picture the cracks are fairly visible but trying to detect them in person is very difficult, even with a magnifying glass and a flashlight. According to multimeter measurements the other two capacitors and rectifier are working, but it's better to replace all of them. 50 year old eletrolytic capacitors have a short life expectancy and the additional work needed to fix all instead of only one is insignificant. Here is a comparison shot of the old components and their modern replacements. After soldering in the new components you enter a paranoid session of measuring every possible combination on the board to ensure you have not accidentally created a short or put any of the components in the wrong way. A failure here is silent and can give you a live Electroboom experience in your own home. Even though it sounds exciting, you really don't want to see it with your own eyes. I don't speak from experience here, and intend to keep it that way. Anyhow, eventually you have to plug the power and try if the machine works. Amazingly enough it did without a hitch. Once you have it running you can truly appreciate how well the mechanical parts of the projector have been designed. It runs silent, smooth and with zero visible jitter. There is only one plastic knob in the entire device. Unfortunately it is the lens focus adjustment wheel, and it has broken off (as you can see in the first image). You can still sort of twist it with your fingers but the experience is inconvenient to say the least. What next? An obvious question some of you might have is "Wouldn't it be more convenient to watch films on a computer than an ancient and potentially deadly projector?" The answer to that is "Yes, it would indeed be." But more on that in a future blog post.📝Nibble Stew
Fixing a super 8 projector from the 70sWarning! Do not try any of this at home! Messing with internals of electronic devices is dangerous and can lead to electrical fires, serious injury and even loss of life. My dad started using a super 8 film camera as early as 1967 (the system was launched in 1965). He stopped doing it in the 1980s as it became pretty much impossible to buy film. Ever since then the films have been stored in multiple cardboard boxes in his basement. Recently he moved to a smaller apartment so all the films and related hardware had to go somewhere else. Namely, to me. Here is a representative sample. The picture does really not make justice to the projector. It is perhaps the only household appliance I have ever owned that could survive a head-on collision with an IBM Thinkpad from the 2000s. The projector weighs 10 kilos and consumes 200 watts when running, half of which is taken by its halogen light bulb. For comparison a typical modern LED light bulb consumes less than 5 watts. The projector has not been used this millennium so unsurprisingly it did nothing when I plugged it in. The back cover could be opened (with a screwdriver) revealing two glass fuses, one of which was burnt. I replaced it and plugged the machine back in. It immediately let loose the magic smoke even though everything was turned off. Fortunately I had kept the back cover open so could see the smoke the second it appeared and managed to cut the power before flames appeared. Unfortunately the smoke originated deep inside the machine so I could not see which component was the source. To get deeper I would have to remove all the covers. That is no small feat, mind you, I had to buy a whole new ratchet set to get all the various screws out. This thing predates printed circuit boards that would tell you which holes belong to which components. Instead all components have been soldered to the board by hand with Japanese meticulousness. The board won't give us any help on deciphering how things should work. Visual inspection also does not reveal any immediately broken components. Neither did poking around with a multimeter. The only life line was that even though a component had started smoking the fuse had not blown. In theory I could plug the machine in for a second and see if smoke appears again. If it does I can see the exact faulty component. At this point I'd like to remind you of the warning at the top of the post. If you have a known broken electrical device, you should never connect it to any sort of a power source. Seek advice from a qualified professional instead. Even if you manage not to burn your house down, electric shocks are nasty and any resulting smoke is almost certainly noxious. Anyhow, after taking sufficient precautions I plugged it back in and immediately got smoke and could decipher what was wrong. One of the main electrolytic capacitors (the one that was in the most inconvenient location, obviously) had dried out and shorted. This caused one of the bridge rectifiers to have its positive and negative output leads short circuited. Here are the problematic components. The dark blue capacitor on the right is the broken one. For some weird reason the three decoupling capacitors have different voltage ratings (16V, 25V and 50V) even though there is only one transformer and input voltage (12 V). The black circles are the bridge rectifiers. The one on the right is the broken one. In this picture the cracks are fairly visible but trying to detect them in person is very difficult, even with a magnifying glass and a flashlight. According to multimeter measurements the other two capacitors and rectifier are working, but it's better to replace all of them. 50 year old eletrolytic capacitors have a short life expectancy and the additional work needed to fix all instead of only one is insignificant. Here is a comparison shot of the old components and their modern replacements. After soldering in the new components you enter a paranoid session of measuring every possible combination on the board to ensure you have not accidentally created a short or put any of the components in the wrong way. A failure here is silent and can give you a live Electroboom experience in your own home. Even though it sounds exciting, you really don't want to see it with your own eyes. I don't speak from experience here, and intend to keep it that way. Anyhow, eventually you have to plug the power and try if the machine works. Amazingly enough it did without a hitch. Once you have it running you can truly appreciate how well the mechanical parts of the projector have been designed. It runs silent, smooth and with zero visible jitter. There is only one plastic knob in the entire device. Unfortunately it is the lens focus adjustment wheel, and it has broken off (as you can see in the first image). You can still sort of twist it with your fingers but the experience is inconvenient to say the least. What next? An obvious question some of you might have is "Wouldn't it be more convenient to watch films on a computer than an ancient and potentially deadly projector?" The answer to that is "Yes, it would indeed be." But more on that in a future blog post.📝Nibble Stew no one will tell you this about bool data type🎥CppNutsMaking an agile version of a Windows Runtime delegate in C++/WinRT, part 9Maybe it doesn't matter. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 9 appeared first on The Old New Thing .📝The Old New Thing
no one will tell you this about bool data type🎥CppNutsMaking an agile version of a Windows Runtime delegate in C++/WinRT, part 9Maybe it doesn't matter. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 9 appeared first on The Old New Thing .📝The Old New Thing C++/sys - A Standard Library Projection to Facilitate the Verification of Run-time Memory Safety🎥CppOnline
C++/sys - A Standard Library Projection to Facilitate the Verification of Run-time Memory Safety🎥CppOnline Modernizing Legacy Audio Plugin Codebases - Lessons from FL Studio’s Plugin Suite - Tomas Medek🎥audiodevcon
Modernizing Legacy Audio Plugin Codebases - Lessons from FL Studio’s Plugin Suite - Tomas Medek🎥audiodevcon Qt Creator 20.0.1 releasedWe are happy to announce the release of Qt Creator 20.0.1! The release improves tool detection and the default session directory for chats in the AI Agent Client Protocol integration , fixes various issues with CMake Presets as well as some crashes, and contains various other improvements.📝Qt Blog
Qt Creator 20.0.1 releasedWe are happy to announce the release of Qt Creator 20.0.1! The release improves tool detection and the default session directory for chats in the AI Agent Client Protocol integration , fixes various issues with CMake Presets as well as some crashes, and contains various other improvements.📝Qt Blog Python Mobile App Development: Bringing PySide6 on iOSPython mobile app development reaches iOS in Qt 6.12. PySide6 developers can ship native iOS apps from the same codebase they already use for Android and desktop, with no Swift or Objective-C rewrite and no second codebase to keep in sync.📝Qt Blog
Python Mobile App Development: Bringing PySide6 on iOSPython mobile app development reaches iOS in Qt 6.12. PySide6 developers can ship native iOS apps from the same codebase they already use for Android and desktop, with no Swift or Objective-C rewrite and no second codebase to keep in sync.📝Qt Blog When a Bug Becomes a Iconic Feature 🎮🎥PVS-Studio
When a Bug Becomes a Iconic Feature 🎮🎥PVS-Studio Meeting C++ Student Showcase presentations🎥MeetingCpp
Meeting C++ Student Showcase presentations🎥MeetingCpp member initializer list [C++ Shorts Lesson 28]🎥Mike Shah
member initializer list [C++ Shorts Lesson 28]🎥Mike ShahWednesday, July 29, 2026
Making an agile version of a Windows Runtime delegate in C++/WinRT, part 8Exceptions hiding in lambda captures. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 8 appeared first on The Old New Thing .📝The Old New Thing PolyBLEP & PolyBLAMP Demystified - Nis Wegmann - ADCx Copenhagen 2026🎥audiodevcon
PolyBLEP & PolyBLAMP Demystified - Nis Wegmann - ADCx Copenhagen 2026🎥audiodevcon Fine-Grained Authorization: The Missing Piece in Agentic AI Security - Shivay Lamba - NDC Sydney🎥NDC Conferences
Fine-Grained Authorization: The Missing Piece in Agentic AI Security - Shivay Lamba - NDC Sydney🎥NDC Conferences glfw setup from source a simple triangle (glfw3) [Episode 1 of 2]🎥Mike ShahHow old is Ann?From “Topics of the Times,” New York Times of 1924-11-17:📝Arthur O’Dwyer
glfw setup from source a simple triangle (glfw3) [Episode 1 of 2]🎥Mike ShahHow old is Ann?From “Topics of the Times,” New York Times of 1924-11-17:📝Arthur O’DwyerTuesday, July 28, 2026
C++26: Reducing undefined behaviourNowadays, safety is in the focus of C++. Whether it’s at committee meetings, conference talks, or hallway discussions, the topic keeps coming up. C++26 made some big steps forward in this area, and one recurring theme is the reduction of cases leading to undefined behaviour. With the words of one of the presented proposals, “undefined behaviour has all but unbounded potential for bad program b...📝Sandor Dargo's BlogMaking an agile version of a Windows Runtime delegate in C++/WinRT, part 7Further explorations into exception safety. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 7 appeared first on The Old New Thing .📝The Old New Thing Beautiful C++ Code - Told Through the Eyes of A Failed AI Prompt - Erich Lohrmann - C++Now 2026🎥CppNow
Beautiful C++ Code - Told Through the Eyes of A Failed AI Prompt - Erich Lohrmann - C++Now 2026🎥CppNow Doors of (AI)pportunity: The Front and Backdoors of LLMs - Kasimir Schulz & Kenneth Yeung🎥NDC Conferences
Doors of (AI)pportunity: The Front and Backdoors of LLMs - Kasimir Schulz & Kenneth Yeung🎥NDC Conferences Introducing the SQL MCP Server - Jerry Nixon - NDC Toronto 2026🎥NDC Conferences
Introducing the SQL MCP Server - Jerry Nixon - NDC Toronto 2026🎥NDC Conferences Threat Modeling Developer Behaviour: The Psychology of Bad Code - Tanya Janca🎥NDC Conferences
Threat Modeling Developer Behaviour: The Psychology of Bad Code - Tanya Janca🎥NDC Conferences How to Break AI Systems (Before Someone Else Does) - Gary Lopez - NDC Toronto 2026🎥NDC Conferences
How to Break AI Systems (Before Someone Else Does) - Gary Lopez - NDC Toronto 2026🎥NDC Conferences Teaching C++ in the age of AI and large language models🎥MeetingCpp
Teaching C++ in the age of AI and large language models🎥MeetingCpp constructors [C++ Shorts Lesson 27]🎥Mike ShahA crosswording miscellanyI just finished reading Natan Last's 2025 book _Across the Universe: The Past, Present, and Future of the Crossword Puzzle._ It was... fatiguing. Now, I myself am a "discursive" writer, so I'm throwing stones from a glass house here; but it seemed to me that Last's _every_ paragraph consisted of three or four anecdotes halfway told, capped off with some nonsensical simile. Open the book at random to page 31: > On December 11, 2022, Eric [Albert] suffered a hemorrhagic stroke of his cerebellum. > He's lucky to be alive: around 50 percent of patients die in a month, half of those within > the first two days. When we first spoke in April 2023, I immediately asked if his language > had been affected, then regretted it. But he was fine, he said. The neurologists don't know > why the stroke happened, or how he recovered his cognition so quickly. He says he repeated the > French he was learning to himself in the ICU. I imagined him, was almost ashamed to imagine him, > saying _ciré ciré ciré, épée épée épée_ — as if the accent marks were stray neurons in need of repair > — or an item from James Joyce's _Finnegans Wake_ I'd just seen in _Word Ways_ because it's the > only "word" with five or more Q's: _Quoiquoiquoiquoiquoiquoiquoiq!_ In Joyce's _Wake_, it's > preceded by the line: "He lifts the lifewand and the dumb speak." I remembered analyses of > Broca's aphasia I'd read studying neuroscience in college [...]📝Arthur O’Dwyer
constructors [C++ Shorts Lesson 27]🎥Mike ShahA crosswording miscellanyI just finished reading Natan Last's 2025 book _Across the Universe: The Past, Present, and Future of the Crossword Puzzle._ It was... fatiguing. Now, I myself am a "discursive" writer, so I'm throwing stones from a glass house here; but it seemed to me that Last's _every_ paragraph consisted of three or four anecdotes halfway told, capped off with some nonsensical simile. Open the book at random to page 31: > On December 11, 2022, Eric [Albert] suffered a hemorrhagic stroke of his cerebellum. > He's lucky to be alive: around 50 percent of patients die in a month, half of those within > the first two days. When we first spoke in April 2023, I immediately asked if his language > had been affected, then regretted it. But he was fine, he said. The neurologists don't know > why the stroke happened, or how he recovered his cognition so quickly. He says he repeated the > French he was learning to himself in the ICU. I imagined him, was almost ashamed to imagine him, > saying _ciré ciré ciré, épée épée épée_ — as if the accent marks were stray neurons in need of repair > — or an item from James Joyce's _Finnegans Wake_ I'd just seen in _Word Ways_ because it's the > only "word" with five or more Q's: _Quoiquoiquoiquoiquoiquoiquoiq!_ In Joyce's _Wake_, it's > preceded by the line: "He lifts the lifewand and the dumb speak." I remembered analyses of > Broca's aphasia I'd read studying neuroscience in college [...]📝Arthur O’DwyerMonday, July 27, 2026
 Dynamic Asynchronous Tasking with Dependencies in C++🎥CppOnlineMaking an agile version of a Windows Runtime delegate in C++/WinRT, part 6Exception-safety, the invisible bug. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 6 appeared first on The Old New Thing .📝The Old New Thing
Dynamic Asynchronous Tasking with Dependencies in C++🎥CppOnlineMaking an agile version of a Windows Runtime delegate in C++/WinRT, part 6Exception-safety, the invisible bug. The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 6 appeared first on The Old New Thing .📝The Old New Thing C++ Weekly - Ep 543 - The constexpr Evolution of std::array🎥Jason Turner
C++ Weekly - Ep 543 - The constexpr Evolution of std::array🎥Jason Turner Workshop: Programming Music and Synthesizers on-the-fly with Pharo - Domenico Cipriani - ADC 2025🎥audiodevcon
Workshop: Programming Music and Synthesizers on-the-fly with Pharo - Domenico Cipriani - ADC 2025🎥audiodevcon Most Expensive Design Mistakes (Ever) and how to avoid them - Clarissa Rodrigues🎥NDC Conferences
Most Expensive Design Mistakes (Ever) and how to avoid them - Clarissa Rodrigues🎥NDC Conferences How to Lie with AI: Understanding Bias, Ethics, and the Hidden Risks in ML - Clarissa Rodrigues🎥NDC Conferences
How to Lie with AI: Understanding Bias, Ethics, and the Hidden Risks in ML - Clarissa Rodrigues🎥NDC Conferences Optimizing your HttpClient usage - Nico Vermeir - NDC Copenhagen 2026🎥NDC Conferences
Optimizing your HttpClient usage - Nico Vermeir - NDC Copenhagen 2026🎥NDC Conferences